
Meet Charles Michael Star Fork
See the white search-box above? It’s added on the website via a simple <script> tag,
no rocket science. You just start typing and results should appear after the third character.
Try typing “test”.
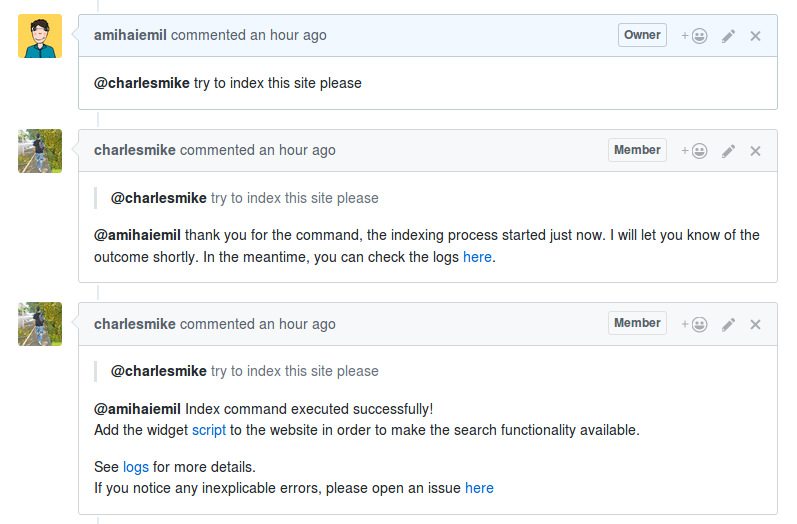
How and where is the content indexed? Well, everything is done by this guy, Chales Michael. Say @charlesmike hello in
any Github issue and see what happens.
I wanted to have basic search functionality on my blog, but I couldn’t find any elegant solution. Before you shout “GOOGLE!”, think that, while they too provide a simple script to embed on your page, the experience is lame: the user starts typing something, hits enter and then is rudely redirected to Google’s page, with a funny syntax in the search-box. It’s the classic Google Search, instructed to look only through your website’s contents.
I figured that, since I have Jekyll seamlessly integrated with Github Pages, it would be nice to have an index/search
service as well. So, as a pet project, I decided to write a small bot which listens for commands and once it receives an index command it crawls and indexes the given website.
The @charlesmike user is only the interface, while the bot itself is deployed somewhere in the AWS cloud and communicates with Github via its API. Once it crawled the content, it sends it to AWS ElasticSearch and instantly makes it searchable via the search widget. Any Github Pages website can use it (standalone website repos or project repos from
the gh-pages branch).
There are a few commands implemented already:
- hello - It will introduce itself;
- index site - indexes the whole website, crawling it as a graph;
- any comment containing the words “index” and “site” will trigger this. Recommended only for small sites, as Selenium is rather volatile. For bigger blogs, try indexing by sitemap.
- index sitemap - index the site represented by a
sitemap.xmlfile.- any comment containing the words “index” and “sitemap”, and also the link to
the sitemap.xml file in markdown (e.g.
index [this](link/to/sitemap) sitemap pls)
- any comment containing the words “index” and “sitemap”, and also the link to
the sitemap.xml file in markdown (e.g.
- index page - indexes a single page;
- the comment has to contain the words “index” and “page”, and also the link to the
page in markdown format (e.g.
index [this](link/to/page) page);
- the comment has to contain the words “index” and “page”, and also the link to the
page in markdown format (e.g.
- delete - deletes the index;
- the comment has to contain the word “delete” and the repo’s name (for double-checking);
The bot will never do any actions on its own. No re-trial, no recurring processes – everything starts with a Github comment addressed to it, always.
Of course, everyone can say hello, but only the repo owner can give other types
of commands. In the near future, the commanders’ list will be configurable via a .charles.yml file.
Feel free to use this if you have a gh-pages website of blog. If you need another scheme of colors for the search widget, just open an issue here or make a PR with it – it’s a small CSS addition.
You can find more details about the bot’s architecture here. If you want to deploy it on your own AWS infrastructure, you can do that easily by setting some system properties, as described here.
